Собственная разработка для прогнозирования цен на газ на основании предоставленных данных

К нам обратился клиент за разработкой модели машинного обучения, которая сможет прогнозировать цены на газ на основе предоставляемых ей данных, рынок – США.
Что было нужно клиенту
Модель машинного обучения, которая самостоятельно сможет прогнозировать цены на газ на рынке США
Что мы сделали
Создали кастомный алгоритм из 6 моделей машинного обучения, который дает результат на уровне лучших рыночных моделей инвестиционных холдингов. Для этого мы предприняли следующие действия:
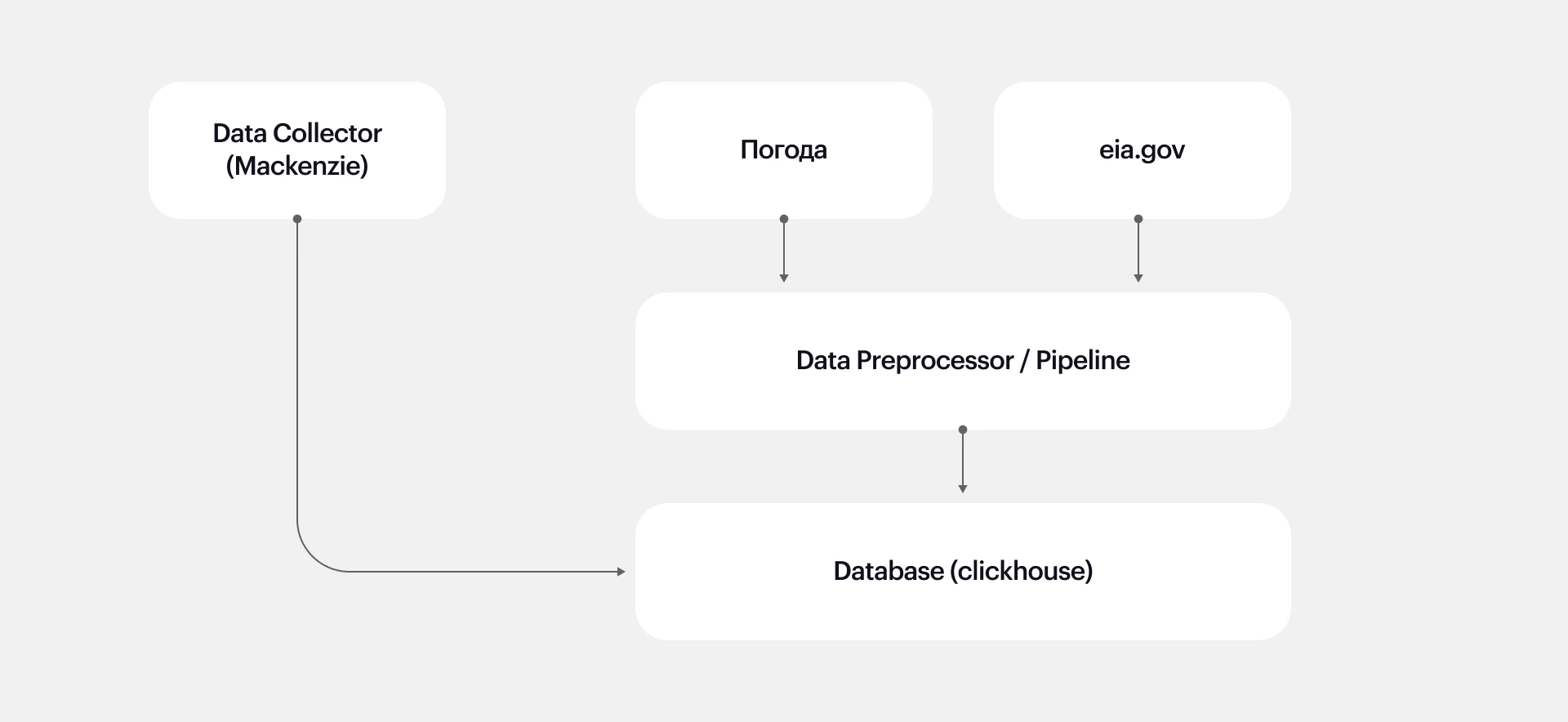
На первом этапе мы провели подготовку, в.т. помогли заказчику сформировать техническое задание для сбора данных и требования для сервера, развернули систему, базы данных, пакетные менеджеры и настроили все необходимые компоненты.
На втором этапе мы исследовали данные: отбирали «мусорные» и добирали необходимые, сопоставляли наши данные с эталонными, использовали множество математических функций и методов для обработки, запускали тестовые модели и гипотезы.
На третьем этапе мы непосредственно строили саму модель: использовали более 30 моделей для отработки разных версий и гипотез, в итоге создали кастомный ансамбль из моделей машинного обучения.
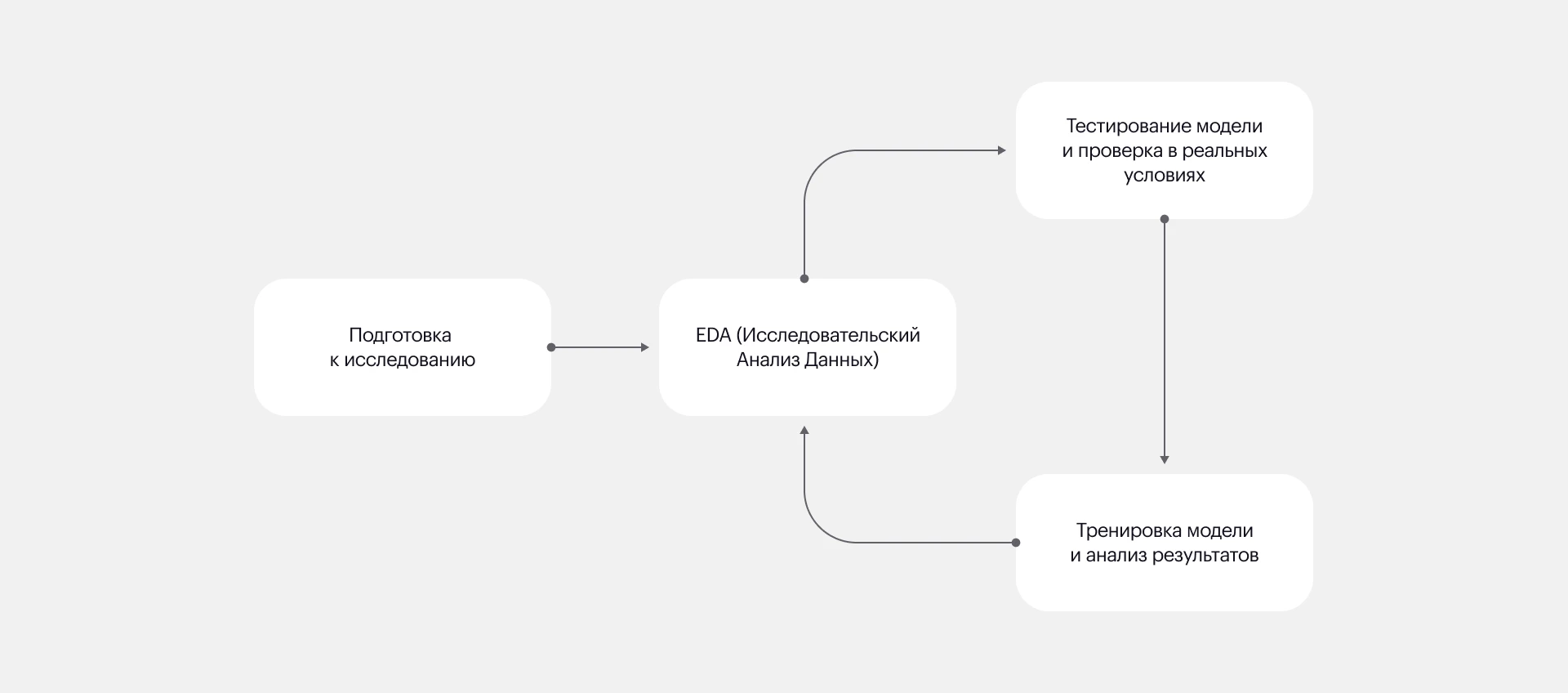
Как мы работали над проектом
Этап 1. Загрузка данных
Этот этап – подготовка к EDA (Исследовательский анализ данных) и построению модели машинного обучения прогнозирования. И здесь же мы столкнулись с первой проблемой – заказчик обратился к нам с проектом, но не подготовил требования и источники для сбора данных.
Мы сформировали техническое задание для сбора и обработки данных, а также требования к серверу. Помогли заказчику подобрать поставщика данных и серверную конфигурацию.
На арендованном сервере развернули систему, базы данных, пакетные менеджеры и настроили компоненты: загружали данные из хранилища к себе, чтобы мы могли их быстрее обрабатывать, написали для этого множество обработчиков (пайплайнов).
Таким образом, мы использовали данные локально, т.к удаленный доступ был медленным и не позволял создавать кастомные SQL-срезы для обработчиков данных.
Данные нам поступали ежедневно от компании Mackenzie. Важно: мы не просто получали готовые данные, мы помогли клиенту найти поставщика и выстроить с ним диалог.
Также важно было большой массив данных правильно сохранить. Вся база данных весила около 1,5 ТБ. С помощью алгоритмов мы поэтапно загружали базу через оперативную память (32 ГБ), для обработчиков использовали срезы и библиотеки Dask.

Этап 2. EDA или исследование данных
Основная задача второго этапа – подготовить данные для работы модели машинного обучения. На этом этапе мы стали дополнительно записывать еженедельные эталонные данные от США (EIA), чтобы сопоставлять их с нашими.
И здесь мы столкнулись с целым рядом трудностей, поскольку большинство ежедневных данных, с которым мы работали, оказались проблемными:
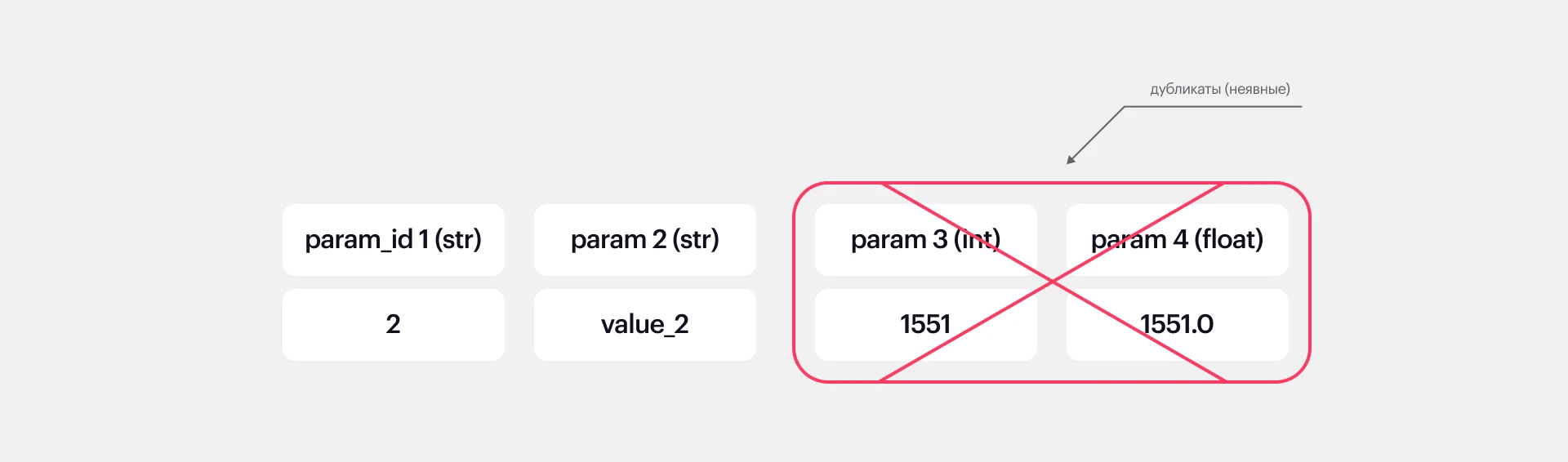
Много «мусорных» данных. Среди ежедневных данных было очень много лишних, которые никак не влияли на нашу задачу. Поэтому мы использовали рекурсивный отбор признаков (RFE).
Дополнительно мы собирали и оценивали каждую фичу, которая может положительно повлиять на целевую метрику модели (цену на газ), также обогащали и считали дополнительные фичи, например, дельту по погоде или месяц/квартал.
Данные по погоде мы собирали отдельно, считали среднее по штатам США, чтобы данные максимально были сопоставимы с эталоном, которые публикуются на сайте eia.gov.
Данные несоразмерные. Проблемные данные поставлялись ежедневно, эталонные от государства – еженедельно. И нельзя было их сопоставить и точно выявить показатели за каждый день.
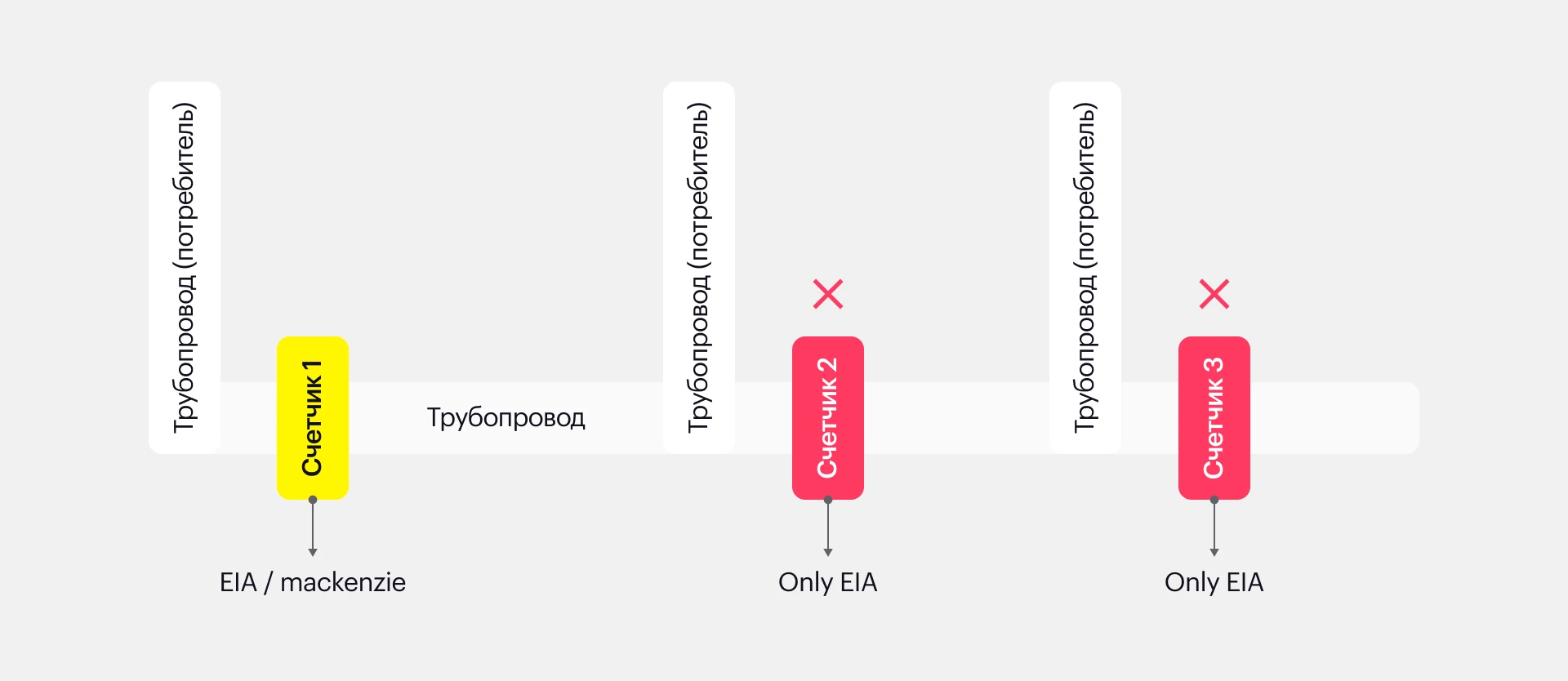
Компания поставляла не все данные со счетчиков. Государство поставляет эталонные данные из своих источников, компания предоставляет ежедневные данные со счетчиков. Счетчики могут учитывать или не учитывать сжиженный газ, через них могут не поступать данные по отдельным хранилищам.
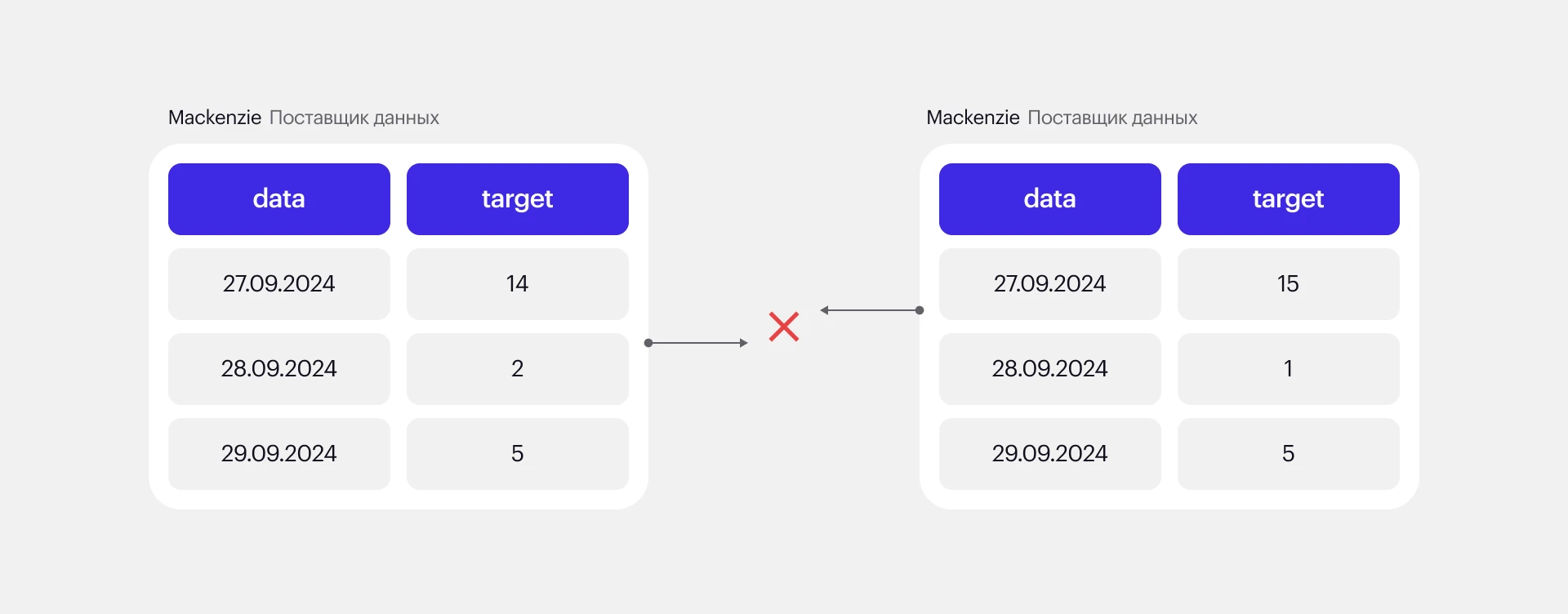
Данные часто менялись. Новые ежедневные данные, предоставляемые компанией, могли не сходиться с теми данными, которая она поставляла ранее. Из-за этого были сложности с обучением модели.
Чтобы модель могла легко работать с большим массивом данных (1,5 ТБ), переучивалась на актуальных данных и корректировала свои ошибки, мы использовали библиотеки:
- Dask – для обработки данных
- Pandas – для работы уже с агрегированными данными
- Skit-learn – для предварительной оценки качества моделей машинного обучения, пайплайнов
- MinMaxScaler/StandardScaler – для стандартизации данных и приведения их в одну величину (например, от 0 до 1, minmax). Это помогает быстро сопоставить данные, у которых сильное искажение относительно нормального распределения, и вбросы.
Это наиболее сложный этап во всем проекте. Обработка данных не прекращалась даже на этапе построения модели, поскольку оба этих этапа тесно связаны друг с другом: если не получается построить модель, мы возвращались к исследованию данных.
Этап 3. Построение модели
На этапе EDA мы уже запускали модель линейной регрессии – она простая и позволяет наиболее быстро протестировать и оценивать первые результаты, для нее не нужна высокая мощность, а результаты по качеству модели легко оценивать.
Также в исследовании мы использовали следующие модели: Darts (в который включен ARIMA/VARIMA, KalmanForecaste, AutoARIMA, CatBoost, RNN (рекуррентные нейронные сети), NHiTS, TCN, TFT, TiDE, а также различные вариации ансамблей с представленными моделями – всего более 300 протестированных комбинаций.
С помощью подбора мы определяли наиболее производительный стек, который далее использовали в работе, среди наших вариантов были GluonTS, Statsmodels, AutoTS, TensorFlow Time-Series / TF-Forecasting, SARIMAX.
Мы провели огромное количество автотестов, создавали ансамбли из моделей и дополнительно обучали их на разных интервалах и данных. Для каждого стека мы трансформировали данные под его требования и писали обработчики, чтобы связать их вместе. Подобрали лучшие гиперпараметры для более удачных ансамблей при помощи Optuna, для оптимизации работы с временными рядами использовали Catboost + xgboost.
Всего для тестов мы использовали около 30 различных математических моделей. После долгих исследований пришли к своему собственному ансамблю из 6 моделей машинного обучения из библиотеки scikit-learn.
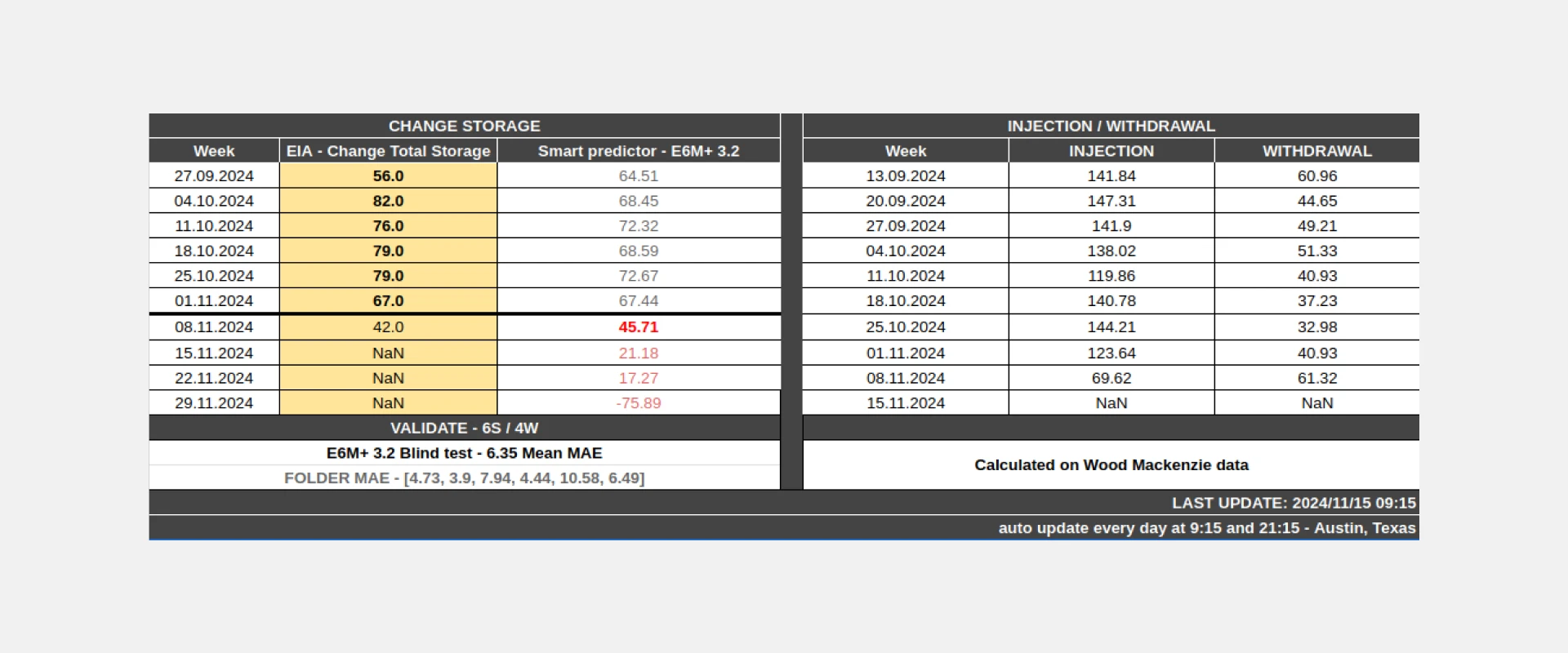
Мы назвали алгоритм «E6M»: он выдавал достоверные прогнозы с минимальной ошибкой как на исторических, так и на тестовых и реальных данных. MAE (Mean Absolute Error, средняя абсолютная ошибка) величиной 6 считалось на дату запуска считалось лучшим конкурентным результатом.
Результат
В итоге положительный результат мы смогли достичь менее, чем за 1 год: около трех месяцев ушло на построение самой модели, остальное время мы ждали данные, отбирали и обрабатывали их.
Несмотря на все сложности работы с данными, в итоге нам удалось максимально приблизить прогноз модели и реальный результат.
С помощью подбора мы определяли наиболее производительный стек, который далее использовали в работе, среди наших вариантов были GluonTS, Statsmodels, AutoTS, TensorFlow Time-Series / TF-Forecasting, SARIMAX.
Нам удалось сократить индекс MAE (Mean Absolute Error, средняя абсолютная ошибка) до 7, а иногда и меньше, что говорит о минимальных ошибках и отклонениях в предсказаниях модели.
Также регулярно мы проводили перетренировки, чтобы модель могла учитывать новые данные и сохранять верный результат.
команда проекта
- руководитель проекта
- аналитик